Serverless architectures are changing the landscape of computing and business by fundamentally de-risking value creation and delivery. Advanced serverless cloud computing is helping solve fundamental problems concerning utility, performance, and security. For over a decade Amazon Web Services has been offering managed infrastructure solutions like EC2, S3, and now Lambda with 100s of other services to choose from. If you are operating a business how do you decide what to invest in to get the edge in 2019? At this stage of the game if you are considering moving to AWS or using it more effectively you definitely want to consider focusing on architecture and more specifically going Serverless where possible.
For 2019, how do you power down that last server in production and go NoOps? More importantly, why do you need to? For the majority of business use cases we can so lets do it! Lets cover 5 ways to crush it on AWS with serverless technologies.
The Case for Serverless
What does Serverless even mean, I thought the cloud already solved the utility computing problem? Serverless means that you can run your code (your business) without provisioning and managing your own compute resource. If you have used AWS for a couple of years now think about the services that ultimately manifest themselves as server instances running in EC2, AWS' flagship compute service that everything is built on top of. Servers that you can see running in your AWS EC2 console are constantly costing you money whether they are being used or not.
We know that we can use application autoscaling to cut down on cost in EC2, but we can't cut it down to zero. With services like Lambda, AWS will start, scale, maintain and "stop" required compute resources. The core underpinnings of services like Lambda are being baked into current and future AWS offerings as well; offering utility computing on demand at a reduced priced. Ultimately less data centers have to be built as computing becomes more efficient from both a provider and consumer perspective overall.
#1 Content Delivery Networks (CDNs)
So you already have a working product, how can you immediately start to benefit from AWS using ,demand based, serverless computing? One easy way to get started and add scale is to take advantage of a content delivery network, CDN. AWS Cloudfront can be used to effectively serve up both static and dynamic content globally at the edge of the network and closest to your customers.
The most important component of any solution is the interface with the customer. Modern interfaces are content heavy, minimize the user interface, and are most often served over mobile networks; it is important that the content reaches the customer quickly over complicated network topologies. We are familiar with static content delivery networks, but additional dynamic content can also be processed in Cloudfront via Lambda@Edge. This allows requests and responses from origin servers to be customized based on customer details. All of these benefits come without provisioning a single server and the pricing model is based on usage along with a generous free tier. Ultimately this means fast response times for users and less servers at the origin, regardless of implementation.
#2 Continuous Integration and Continuous Delivery (CI/CD)
For larger software development shops sometimes the challenge is simply getting the code out the door. You've implemented agile best practices and are pushing features out the door continuously. Unfortunately your Jenkins server isn't keeping up and it is becoming a bear to manage in its own right. The needs for that critical infrastructure only grow as you add more projects to the mix and you've had a couple of outages. Your ops team is already working on AWS migrations so you get the following proposal from an operations team member:
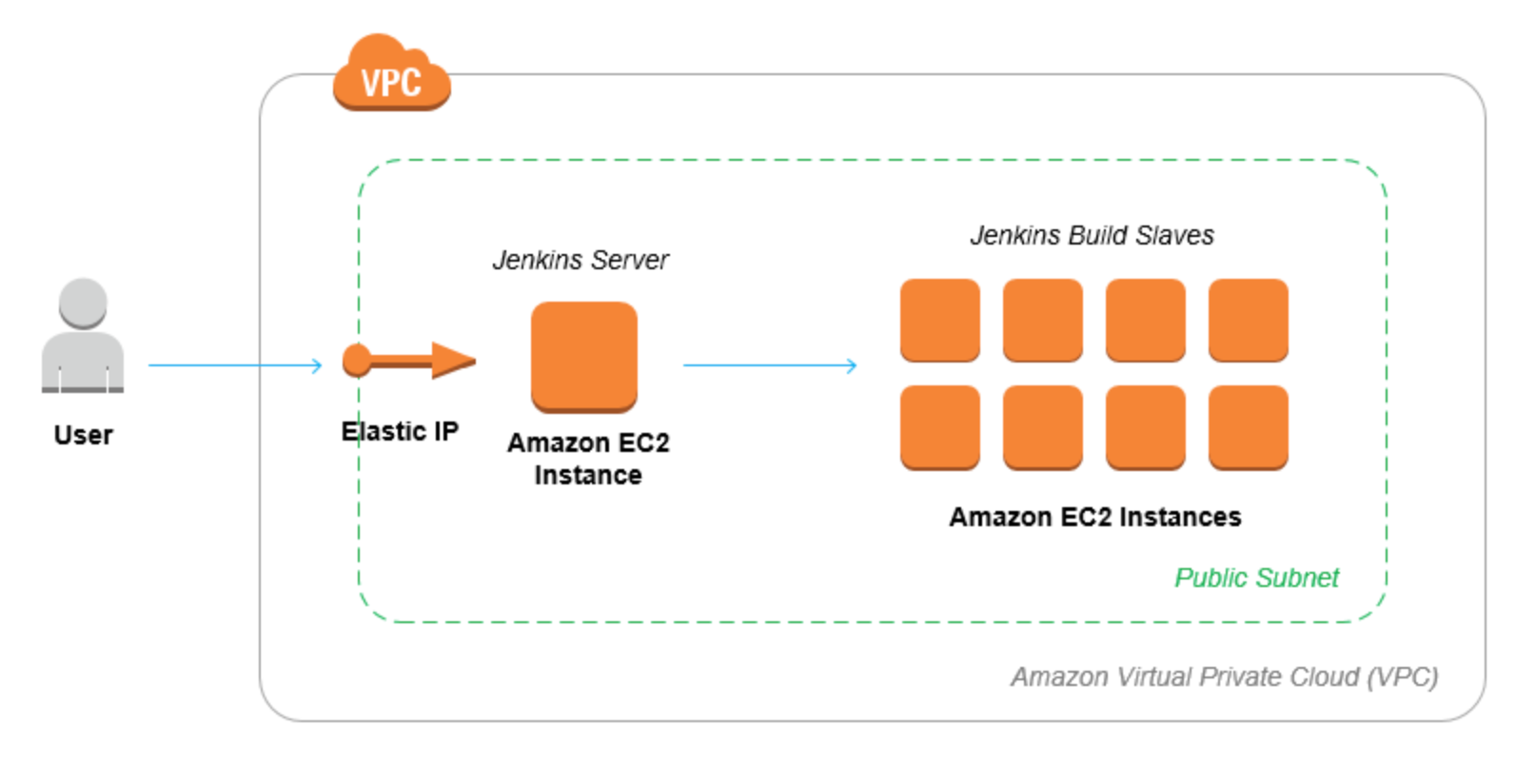
It is enough to make your head spin and the needs of your build server are only increasing as you adopt container architectures. What do you do as a dev manager that wants to increase overall productivity for your team? Try another way! The good news on this front is that AWS went through many of the same challenges as they increased throughput for their own organization a few years ago. With that came AWS CodePipeline and the suit of tools that come with it for you to manage CI/CD at enterprise scale, with no servers!!! The family of developer tools is as follows:
- AWS CodeCommit - managed Git repos (don't use these to store your source repos! They are a lightweight way for you to publish your code to a pipeline)
- AWS CodeBuild - you can define your entire build process in a single yaml file. If you need more than that you are probably not deploying a microservice and need to break things apart
- AWS CodeDeploy - now you can normalize your release process for any application on almost any platform in AWS and on prem. You'll know what was deployed and when, with full reporting every step of the way.
Once again, all this power and not a single piece of infrastructure to manage. In simple setups your team will need nothing more than an AWS account to get started. In more complicated environments and larger teams you can use a combination of AWS Organizations and AWS IAM (Identity and Access Management) to provision access to not only AWS Development tools like Codepipeline, but anything running in AWS.
#3 On-Premises Network Attached Storage (NAS)
On-Prem? I thought we were talking about the cloud, AWS, and Serverless? What if I told you that AWS S3 was also the solution to storage that is bursting at the seams inside of your on-prem colo or datacenter? A viable alternative to upgrading hardware is proactively shifting certain use cases to S3 for long term affordable infinite storage using an AWS File Gateway.
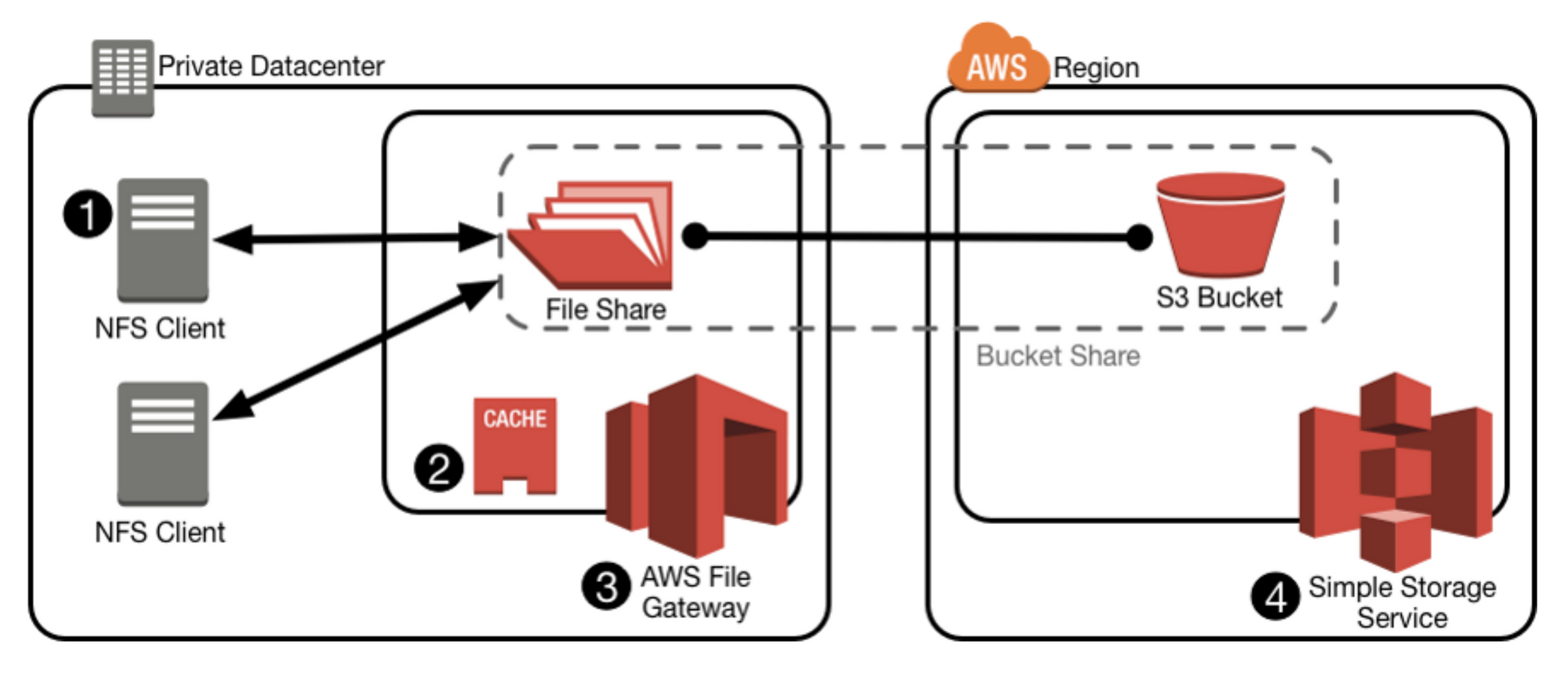
One approach to on-premises environments, where storage resources are reaching capacity, is to migrate colder data to the file gateway to extend the life span of existing storage systems and reduce the need to use capital expenditures on additional hardware. When you add the file gateway to an existing storage environment, on-premises applications can take advantage of Amazon S3 storage durability, consumption-based pricing,and virtual infinite scale, while ensuring low-latency access to recently accessed data over NFS. The AWS File Gateway can be provisioned as hardware or as a VM in VMWare. This is perfect for home directories and legacy applications that have archival data. The story gets even better when you take into consideration S3's new "Intelligent-Tiering" capability.
The S3 Intelligent-Tiering storage class optimizes costs by automatically moving data to the most cost-effective access tier, without performance impact or operational overhead. It works by storing objects in two access tiers: one tier that is optimized for frequent access and another lower-cost tier that is optimized for infrequent access. S3 monitors access patterns of the objects in Intelligent-Tiering, and moves the ones that have not been accessed for 30 days to the infrequent access tier. If an object in the infrequent access tier is accessed, it is automatically moved back to the frequent access tier. So you can significantly reduce storage costs at scale on prem by eliminating storage servers, NAS, and SANS for many use cases. The only thing worse than servers needing to be managed is servers with hard drives that need to be managed!!!
#4 Database as a Service (DBaaS)
If you are still managing databases it means you definitely are not in the cloud or you need to take a hard look in the mirror. The three pillars of cloud computing are compute, network, and storage. Any database of significance is going to grow very large and embody all of the pillars at the same time. Most database solutions are going to make compromises around total storage size, query response time, or query complexity. This is in addition to transactional properties, commonly referred to as ACID (Atomicity, Consistency, Isolation, Durability). Traditional database administrators and engineers manage complicated configuration and core infrastructure by hand to operate databases at large and growing scales. The world has been made small by connected devices that have outsized the amount of data and content we produce on a per second basis; 300 million photos are posted to Facebook per day. Each photo has a database entry... Facebook can afford to manage its own costly data centers and even invent its own databases, but most don't have that luxury. Fortunately AWS has an ever growing army of database services for you to choose from, including solutions that are taken for granted. It should be no surprise that some of the best solutions involve minimal to no server configuration!
To this day DynamoDB is still an 8th wonder of the world and it now does more than ever to be your first and last chance at full scalability when it comes to your business. DynamoDB provides zero compromise when it comes to scale and speed. Recent DynamoDB advances now raise the bar in terms of durability as well by providing regional replication and daily snapshot backups at any scale! If you begin a new project on AWS you should consider Lambda and DynamoDB together. They work like peanut butter and jelly and is the easiest path hands down for delivery modern, large scale, microservice backed, capabilities to startups and enterprises alike. In addition, at the time of this writing, DynamoDB is now the only non-relational database that supports transactions across multiple partitions and tables. Amazon is chipping away the reasons to use a standard relational database for greenfield projects.
The Aurora managed database service is the fastest growing service in AWS history. That is a testament to how difficult it is to manage traditional relational databases at any scale. Real businesses require sophisticated transaction processing and analytics that only SQL can provide. One of the best solutions in the overall Aurora suite hands down has to be Aurora PostgreSQL. You get the power of one of the most advanced databases in the world with the scale and performance that AWS provides. PostgreSQL is becoming the de facto standard interface for large scale SQL workloads, both on the open source front and commercially. In recent years Google has made their spanner database commercially available which can scale horizontally in a geo replicated fashion. There are open source variants such as cockroachDB that require management. This is speculation, but don't be surprised if AWS does further worker to integrate the storage backend of PostreSQL with DynamoDB for unlimited scalability. I believe the first signs of that can be seen in their Amazon Quantum Ledger Database (QLDB). QLDB is an amazing append only system of record that AWS is now exposing to any business, at any scale! You still have to think about your specific use case, but you can hold off on expensive database and system administrators to keep the heart of your business up and running.
#5 Firecracker!
This brings us full circle in our discussion of serverless computing and presents an exciting wildcard! Firecracker is the open source microVM technology that powers management free container services like AWS Lambda and Fargate! Firecracker can launch a microVM in as little as 125 ms and is built with many security isolation levels in place. Lambda is over 4 years old and provides virtually infinite scalability and elasticity in modern compute architectures.
Lambda functions truly are the generalized universal event trigger. The fact that HTTPS is the dominant Internet protocol means Lamba dominates as an implementation for API frontends. With Lambda you can you can run compute with zero administration and true subsecond utility metering to manage costs.
Amazon Fargate uses the same microVM architecture as Lambda to deliver a reimagined backend, scalable, always-on, mirror of the network topologies we are familiar with seeing in EC2! With full networking and OS support you can run any Docker container or network of containers in a scalable, maintenance free fashion. Security and access control works using VPCs, subnets, security groups, load balancers... all of the datacenter building blocks we have mastered in the traditional EC2 environment. Fargate puts comprehensive general computing on rails.
In Summary
We covered quite a few solutions offered by AWS under the mantles of serverless and fully managed. These solutions don't work in isolation of course and are meant to be composed together into working solutions to solve real world problems. If you are interested in going serverless or just getting started with AWS, feel free to reach out to us. We are happy to sit down over coffee or virtually to just chat about your needs.
Next Up
In our next DevOps post we will get going on a working solution for a particular itch we have at Rocket Insights. We'll pick from the basket of technologies we have touch on to actually show what this looks like from start to finish. So stay tuned!